Table of Contents
Introduction
In previous articles, we’ve compared Puget Systems’ new mobile workstation against desktops and Apple’s MacBook Pro M3 Max using our content creation benchmarks and an in-depth analysis of battery life, thermals, and noise. Today, we’ll explore a variety of AI workloads ranging from running local LLMs, Stable diffusion, and commercial AI tools to see how the Puget Mobile 17” compares to the MacBook Pro M3 Max.

Image
In large part due to their unified memory architecture, M-series Macs are a popular choice for LLM inference. Although the GPU in the MacBook Pro doesn’t boast the most impressive numbers in terms of raw compute performance, it has access to the system memory at a relatively high bandwidth compared to DDR5 RAM (outside of high-end eight-channel configurations). This means the MacBook Pro should be able to execute inference with larger models while maintaining good performance without using multiple GPUs together, as most AI-focused systems do in order to pool enough high-bandwidth memory capacity for effective use.
On the other hand, the Puget Mobile features a 4090 Mobile 16GB GPU, which allows access to the plethora of software projects designed and optimized for CUDA. While the PC does not feature the unique unified memory architecture, the 4090 Mobile 16GB does have a higher VRAM bandwidth when considered on its own. That, combined with the highly performant Intel Core i9-14900HX CPU, should add up to make the Puget Mobile an excellent platform for running smaller LLMs and other generative models like Stable Diffusion.
Test Setup
Puget Mobile 17″
| Price: $3,925 |
| Laptop Model: Puget Systems C17-G |
| CPU: Intel Core i9-14900HX |
| RAM: 2x DDR5-5600 32 GB (64 GB total) Bandwidth: 89.6 GB/s |
| GPU: NVIDIA GeForce RTX 4090 Mobile 16 GB VRAM Bandwidth: 576 GB/s |
| Storage: Samsung 980 Pro 2 TB |
| OS: Windows 11 Pro 64-bit (22631) |
Apple M3 Max MacBook Pro 16″
| Price: $4,599 |
| Laptop Model: Apple MacBook Pro (M3 Max) |
| CPU: M3 Max 16-core |
| RAM: 64 GB Unified Memory Shared Bandwidth: 400 GB/s |
| GPU: M3 Max 40-core Shared Bandwidth: 400 GB/s |
| Storage: 2 TB Integrated Storage |
| OS: MacOS Sonoma 14.3 |
Benchmark Software
| llama.cpp build 628b2991 (2794) |
| ExLlamaV2 v0.0.21 via TabbyAPI May 2024 |
| Stable Diffusion WebUI Forge f0.0.17v1.8.0rc |
| ComfyUI May 2024 |
All testing was performed with both systems plugged into wall power. The MacBook Pro was configured for its “High Power” Energy Mode, while the Puget Mobile was set to its “Performance” preset.
The llama.cpp testing was performed with the built-in llama-bench executable. For the MacBook Pro, we compiled llama.cpp manually, which enables Metal support by default. We used the provided CUDA 12.2 binaries for the Puget Mobile. Each test was run five times, and the results were averaged.
ExLlamaV2 testing was performed via Text generation web UI, using a ~500 token prompt. Each test was run five times, and the results were averaged.
In both Stable Diffusion front ends we tested with, the Puget Mobile was configured for pytorch cross-attention, while the MacBook Pro used sub-quadratic cross-attention. Each test was run twice, and the results were averaged.


LLM Inference – llama.cpp
llama.cpp is a popular and flexible inference library that supports LLM (large language model) inference on CPU, GPU, and a hybrid of CPU+GPU. The project states that “Apple silicon is a first-class citizen” and sets the gold standard for LLM inference on Apple hardware. It supports half, full, and even double precision but is more commonly used with quantizations between 2 and 8 bits per weight(bpw). llama.cpp is also the backbone of many other LLM inference projects, such as Ollama and LMStudio.

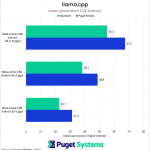






Starting with Meta’s newly released Llama 3 8B instruct model, we see that both systems have excellent performance in prompt processing and token generation. The Puget Mobile’s prompt processing is significantly faster (over 7 times faster in fp16!), but the use-case of the model heavily impacts whether this performance is actually beneficial. In a typical chatbot scenario, prompts are generally short and would be processed practically instantly on either system. However, if the LLM is frequently used to summarize large bodies of text, prompt processing performance is much more impactful.
Compared to prompt processing, the two systems are much closer in performance when it comes to token generation (chart #2). Using the 4-bit K_M quantization, the Puget Mobile leads by about 22% but pulls further ahead as we move to the 8-bit (27%) and the fp16 (38%) versions. Still, both systems are plenty capable of running a smaller model, such as Llama 3 8B.
Moving to the 70B version of Llama 3, we see how the architectural differences between the systems can flip the script depending on the model used. Unlike the 8B model, the 70B is too large to fit entirely within the 16GB of VRAM on the PC’s 4090 Mobile GPU, so the model must be partially offloaded to the much slower system RAM. This impact is clearly seen during token generation, with the MacBook Pro generating tokens at a little more than five times the rate of the Puget Mobile. The unified memory architecture showcases its strengths when loading large models.
Something to note, though, is that because the laptop configuration we tested has 64GB of dedicated system RAM and 16 GB of dedicated VRAM, it actually has a combined 80GB of memory compared to the MacBook Pro’s 64GB unified memory. This allowed it to run an 8-bit Llama 3 70B quantization, whereas the MacBook Pro could not. Admittedly, the 128GB MacBook Pro could load that model for an additional $800 on the price tag. The Puget Mobile’s RAM can also be upgraded, to a total of 112GB (96GB RAM + 16GB VRAM) to allow for larger models as well. The cost to do so is far less than Apple (only about $100), but keep in mind that the more of a model that is offloaded into non-unified RAM, the larger the performance impact, so Apple will still have a performance lead for those larger models.
LLM Inference – ExLlamaV2
Without CUDA or ROCm support, some inference libraries are unavailable on the MacBook Pro. One popular example is ExLlamav2, which provides fast inference, supports quantization levels between 2 and 8 bpw as floats, and context caching in 16, 8, or 4 bits. The option to select the bits per weight as a float is great for quantizing a model to just the right size for your hardware.
For example, if a model is just slightly too large to load at 6.0 bpw, we can try with 5.75 bpw instead of dropping all the way down to 5.0 bpw. Additionally, saving the context with a lower precision can greatly reduce VRAM usage with little effect on perplexity. We found that with the Puget Mobile, CodeLlama-34B-exl2:3.0bpw with a context window of 16384 tokens was too much to fit into 16GB of VRAM. Shrinking the context window to a lower value is an option, but by using the 8-bit cache option instead, we can fit the model into our VRAM allowance while maintaining the full context window of 16384 tokens.



System Image
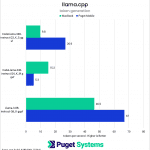
Unlike with llama.cpp, we were unable to get prompt processing statistics to output when using ExLlamav2, so these charts only display token generation. However, when using a prompt of roughly 3500 tokens, token generation for CodeLlama-34B-instruct-exl2 would start in about 3 seconds, suggesting a prompt processing speed of somewhere around 1200 tokens per second. Llama-3-8B-instruct-exl2’s token generation started within a second, which is what we would expect given the multi-thousand token per second prompt processing results we see with Llama-3-8B in llama.cpp.
We chose to include some comparisons to llama.cpp benchmarks (chart #2) using a 3-bit quantization for CodeLlama-34B-instruct and a 6-bit quantization for Llama-3-8B-instruct to match the bpw levels of ExLlamav2. ExLlamav2’s performance was excellent, but it was somewhat surprising that the results for Llama-3-8B on both backends averaged out to 67 tokens per second. We suspect this is likely due to a CPU performance bottleneck, which becomes more important when using smaller, faster models. During token generation with Llama-3-8B-instruct-exl2, the task manager indicated 100% CPU utilization across all cores and between 80-90% GPU usage, whereas with CodeLlama-34B-instruct-exl2, CPU utilization was only ~15% with 90-100% GPU usage.
One interesting artifact we found was that across all 3-bit CodeLlama-34B-instruct quantizations we tried on the MacBook Pro, the performance was notably slower than with the same model using a 4-bit quantization of the same model. CodeLlama-34B-instruct.Q3_K_S.gguf lost a little over 5 tokens per second compared to CodeLlama-34B-instruct.Q4_K_M. And again, on the Puget Mobile, we can see the performance impact of offloading layers to RAM, as CodeLlama-34B-instruct.Q4_K_M was unable to fit within the VRAM budget, unlike the Q3_K_M version.
Although more testing is needed to confirm, it may be the case that when running larger models entirely within the GPU using CUDA, ExLlamav2 is the more performant option, while the choice of backend becomes less important when using smaller models.


Note about Stable Diffusion Optimizations
Like TensorRT for NVIDIA hardware, Apple hardware has an optimization technique for converting Stable Diffusion models to Core ML to reduce size and improve performance. However, we chose not to include performance testing with those optimizations for a few reasons. One is that even with optimizations, the performance is still not competitive against pytorch+CUDA (a benchmark for 1024×1024 SDXL on the Core ML Stable Diffusion repo lists the performance of the M2 Ultra at 1.11 it/s.)
Second, if we were to include an optimization method for Apple hardware, then it would only be fair to compare it to TensorRT on NVIDIA hardware, which would only further widen the performance gap. Finally, the Core ML optimizations are very restrictive, much like earlier versions of TensorRT, in that converted models can only support a single resolution, and LoRAs must be baked into the model at the time of conversion, and this lack of flexibility diminishes the appeal of the Core ML optimizations for Stable Diffusion.
Stable Diffusion WebUI Forge & ComfyUI




System Image
With roughly 6.5 times the speed for single image generation and 7.5 times for multi-image batch generation, the Puget Mobile commands a strong performance lead over the MacBook Pro in Stable Diffusion WebUI Forge.
Both systems achieved slightly better performance when moving to ComfyUI, especially on the MacBook Pro, which had its single image generation speed increase by slightly over 20%. Although this technically did narrow the gap between the two systems, the Puget Mobile can still generate images at nearly 6 times the MacBook Pro’s pace.
In summary, partly because the unified memory architecture is not necessary for Stable Diffusion and partly because of how good NVIDIA is for this type of workload, our PC laptop is going to be many times faster than even the fastest MacBook Pro.
Commercial AI Tools for Content Creation
In this section, we move away from open-source generative AI tools and instead examine utility AI tools found in popular creative applications like Adobe Photoshop and Blackmagic DaVinci Resolve, both tested as part of our PugetBench suite of benchmarks.


System Image
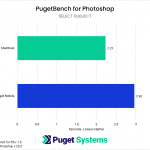
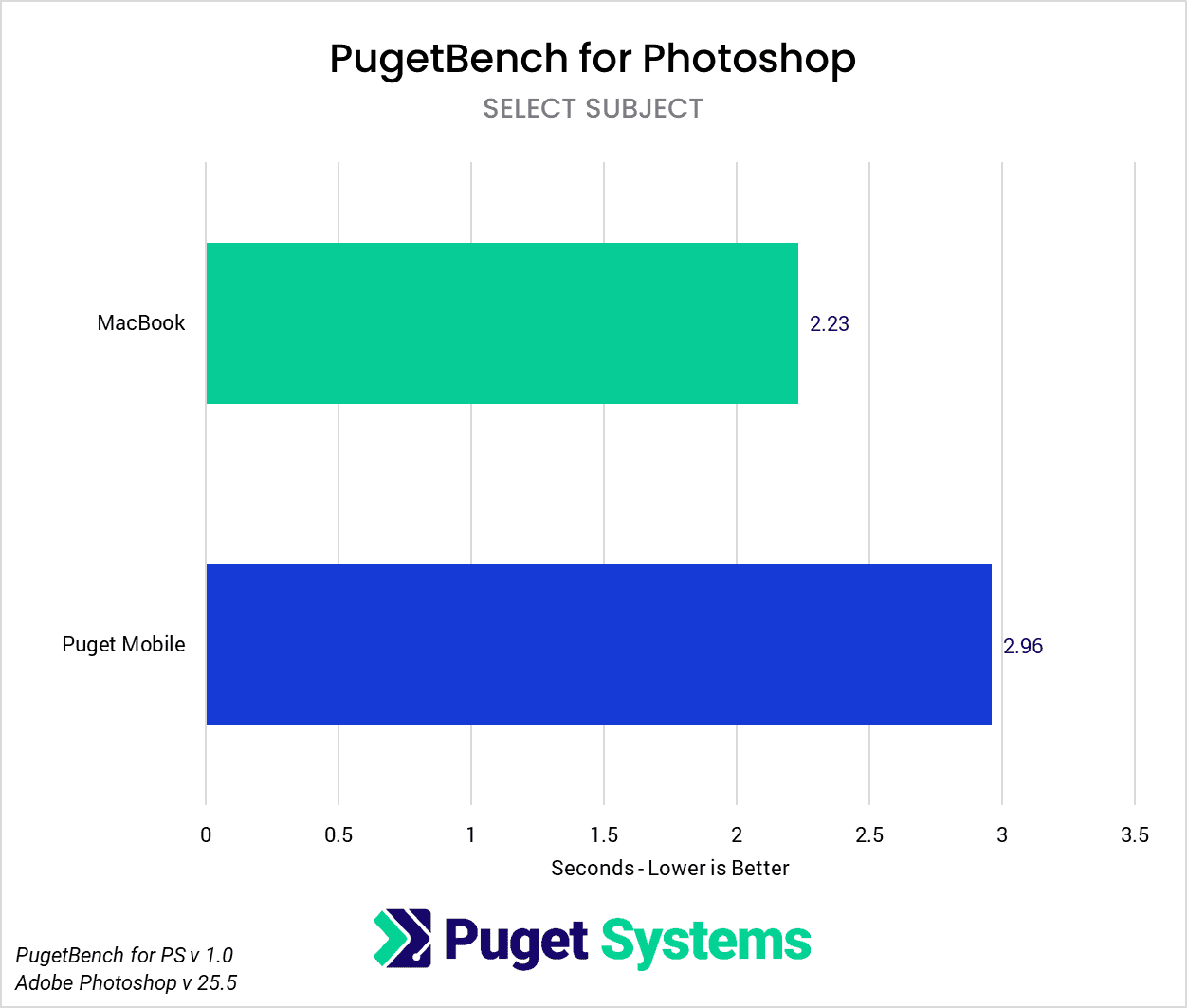
Currently, the only major AI tool within Adobe Photoshop that uses local computing resources is the “select subject” tool. Both systems completed this test in between two and three seconds, but the MacBook Pro finished processing about 25% faster than the Puget Mobile.
DaVinci Resolve Studio, on the other hand, has a large number of “Neural Engine” AI-powered tools that are tested in an upcoming version of our benchmark, including super scaling, face refinement, audio transcription, video stabilization, scene cut detection, and others. The score listed in the chart above represents a geometric mean of all of the individual tests, fifteen in total. The Puget Mobile not only outperforms the MacBook Pro in all but one of the tests (scene cut detection) but achieves twice the performance or more in eleven of the tests.
Final Thoughts
Between Apple’s Macbook Pro M3 Max and the Puget Systems Mobile 17” Workstation, there are very clear pros and cons that make one, or the other, a stronger choice. Starting with the MacBook Pro M3 Max, it a great choice for running larger LLMs that cannot fit within the Puget Mobile’s VRAM, such as the 70B family of Llama models. Although the Puget can certainly run these models as well, its strengths are more evident with models that can be loaded entirely within VRAM and accelerated with CUDA. On top of that, considering the vast majority of development in AI/ML is currently done with CUDA support in mind, having an NVIDIA GPU in your workstation means a lot in terms of having a broad base of supported software.
In the Stable Diffusion ecosystem, Apple is currently not competitive performance-wise, and anyone whose workflow will heavily utilize local Stable Diffusion image generation should look towards workstations with an NVIDIA GPU.
Adobe is still in the early stages of implementing locally powered AI tools (many of their more popular tools like Generative Fill, for example, are cloud-based), but currently the MacBook Pro has a slight lead for the “select subject” tool within Photoshop. However, the Puget Mobile is the clear performance winner within DaVinci Resolve’s suite of “Neural Engine” tools, often performing two or more times faster.
Once again, setting aside variables like battery life, thermals, and noise (which we tested in a dedicated article available here), if your primary desire in a mobile workstation is to run larger LLMs (70B+) with relatively good performance compared to more elaborate designs like multi-GPU desktops, then the MacBook Pro’s unified memory makes it a great choice for that workload. However, if you are looking for a mobile system that has the flexibility to run medium and smaller-sized LLMs (≤34B), along with Stable Diffusion or other projects optimized for CUDA, all with commendable performance, then the Puget Mobile is the superior option.
If you do decide to go with a PC mobile workstation, our Laptop Workstations are currently available for sale. Or, if a desktop workstation is more fitting for your needs, the Puget Systems workstations on our solutions page are tailored to excel in various software packages. If you prefer to take a more hands-on approach, our custom configuration page helps you to configure a workstation that matches your exact needs. Otherwise, if you would like more guidance in configuring a workstation that aligns with your unique workflow, our knowledgeable technology consultants are here to lend their expertise.
Looking for a content creation workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.