Table of Contents
Introduction
In our recent Puget Mobile vs. MacBook Pro for AI workflows article, we included performance testing with a smaller LLM, Meta-Llama-3-8B-Instruct, as a point of comparison between the two systems. Interestingly, when we compared Meta-Llama-3-8B-Instruct between exllamav2 and llama.cpp on the Puget Mobile, we found that they both achieved the exact same token generation speeds despite the difference in inference libraries, theoretically due to a CPU bottleneck.

Image
To determine if and when a specific CPU or platform change could have a sizable impact on LLM performance, we want to expand on that testing today, looking at another smaller-sized LLM, Phi-3-mini-4k-instruct (a 3.8B parameter model), across several platforms. If it’s true that GPU inference with smaller LLMs puts a heavier strain on the CPU, then we should find that Phi-3-mini is even more sensitive to CPU performance than Meta-Llama-3-8B-Instruct.
Although llama.cpp can be run as a CPU-only inference library, in addition to GPU or CPU/GPU hybrid modes, this testing was focused on determining what impact (if any) the CPU/platform choice has specifically during GPU inference.
Test Setup
Like in our notebook comparison article, we used the llama-bench executable contained within the precompiled CUDA build of llama.cpp (build 3140) for our testing. However, in addition to the default options of 512 and 128 tokens for prompt processing (pp) and token generation (tg), respectively, we also included tests with 4096 tokens for each, filling the context window of the model. As we can see in the charts below, this has a significant performance impact and, depending on the use-case of the model, may better represent the actual performance in day-to-day use.
For this testing, we looked at a wide range of modern platforms, including Intel Core, Intel Xeon W, AMD Ryzen, and AMD Threadripper PRO. We tested with both an NVIDIA GeForce RTX 4080 and RTX 4090 in order to see if different GPUs had an impact on performance. Note that we are only including single GPU configurations, as these smaller models are unlikely to be paired with dual or quad-GPU configurations. Full system specs for each platform we tested are listed below:
Shared System Specs
| GPUs: NVIDIA GeForce RTX 4080 16GB Founders Edition NVIDIA GeForce RTX 4090 24GB Founders Edition Driver Version: Studio 555.85 |
| PSU: Super Flower LEADEX Platinum 1600W |
| Storage: Samsung 980 Pro 2TB |
| OS: Windows 11 Pro 64-bit (22631) |
Platform Specs
Intel Core
| Motherboard: Asus ProArt Z690-Creator WiFi BIOS version: 3603 |
| CPUs: Intel Core i5-14600K Intel Core i7-14700K Intel Core i9-14900K |
| RAM: 2x DDR5-5600 32GB (64GB total) Running at 5600 Mbps |
Ryzen Desktop
| Motherboard: Asus ProArt X670E-Creator WiFi BIOS version: 1602 |
| CPUs: AMD Ryzen 7 7700X AMD Ryzen 9 7900X AMD Ryzen 9 7950X |
| RAM: 2x DDR5-5600 32GB (64GB total) Running at 5200 Mbps |
Xeon
| Motherboard: Supermicro X12SPA-TF 64L BIOS version: 1.4b |
| CPU: Intel Xeon W-3335 |
| RAM: 8x DDR4-3200 16GB ECC Reg. (128GB total) Running at 3200 Mbps |
Threadripper
| Motherboard: Asus Pro WS WRX90E-SAGE SE BIOS version: 0404 |
| CPUs: AMD Ryzen Threadripper Pro 7985WX AMD Ryzen Threadripper Pro 7995WX |
| RAM: 8x DDR5-5600 16GB (128GB total) Running at 5200 Mbps |
Benchmark Software
| llama.cpp build a9cae480 (3140) |
| Phi-3-mini-4k-instruct Phi-3-mini-4k-instruct-q4.gguf |


Results
System Image
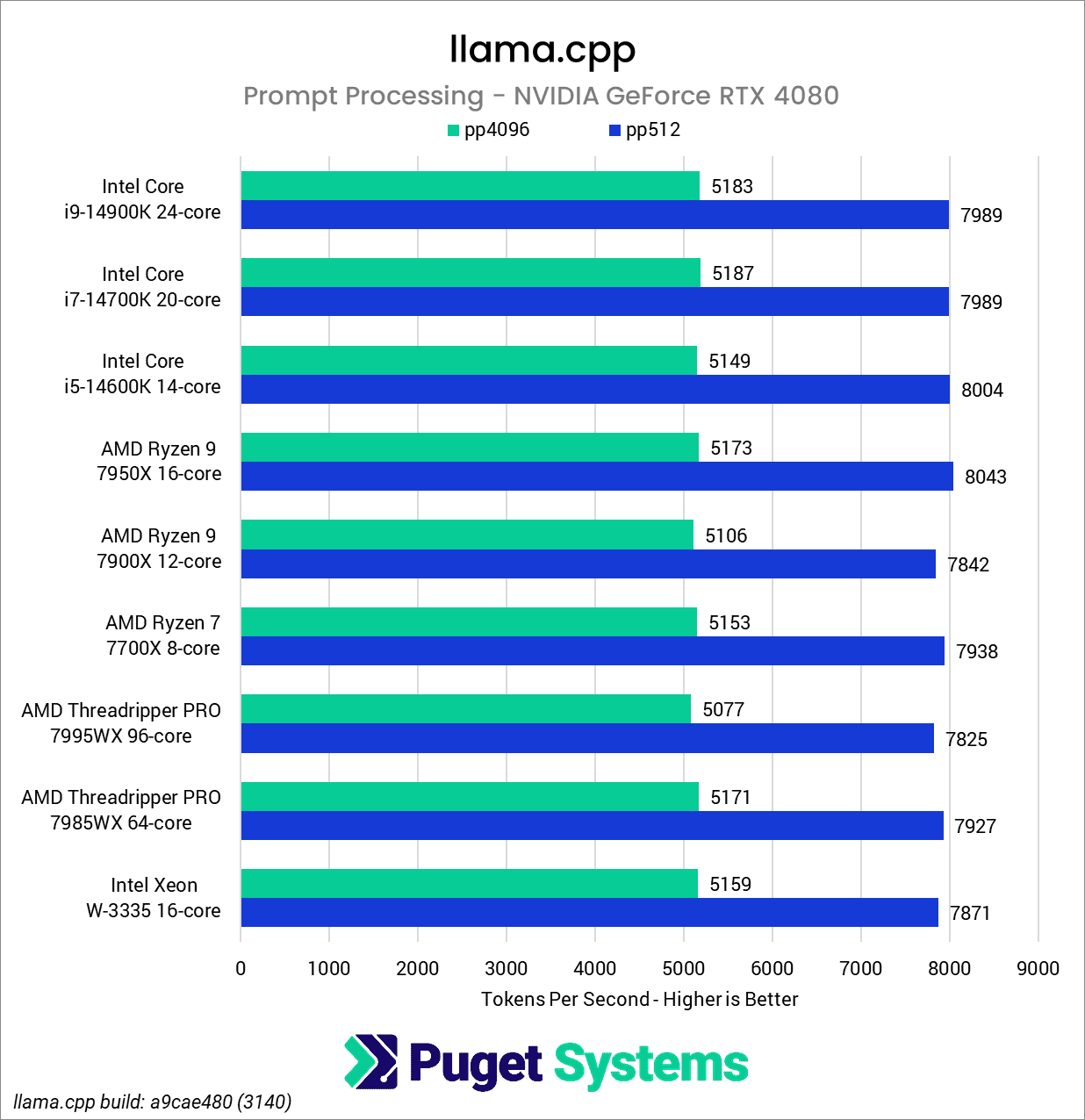
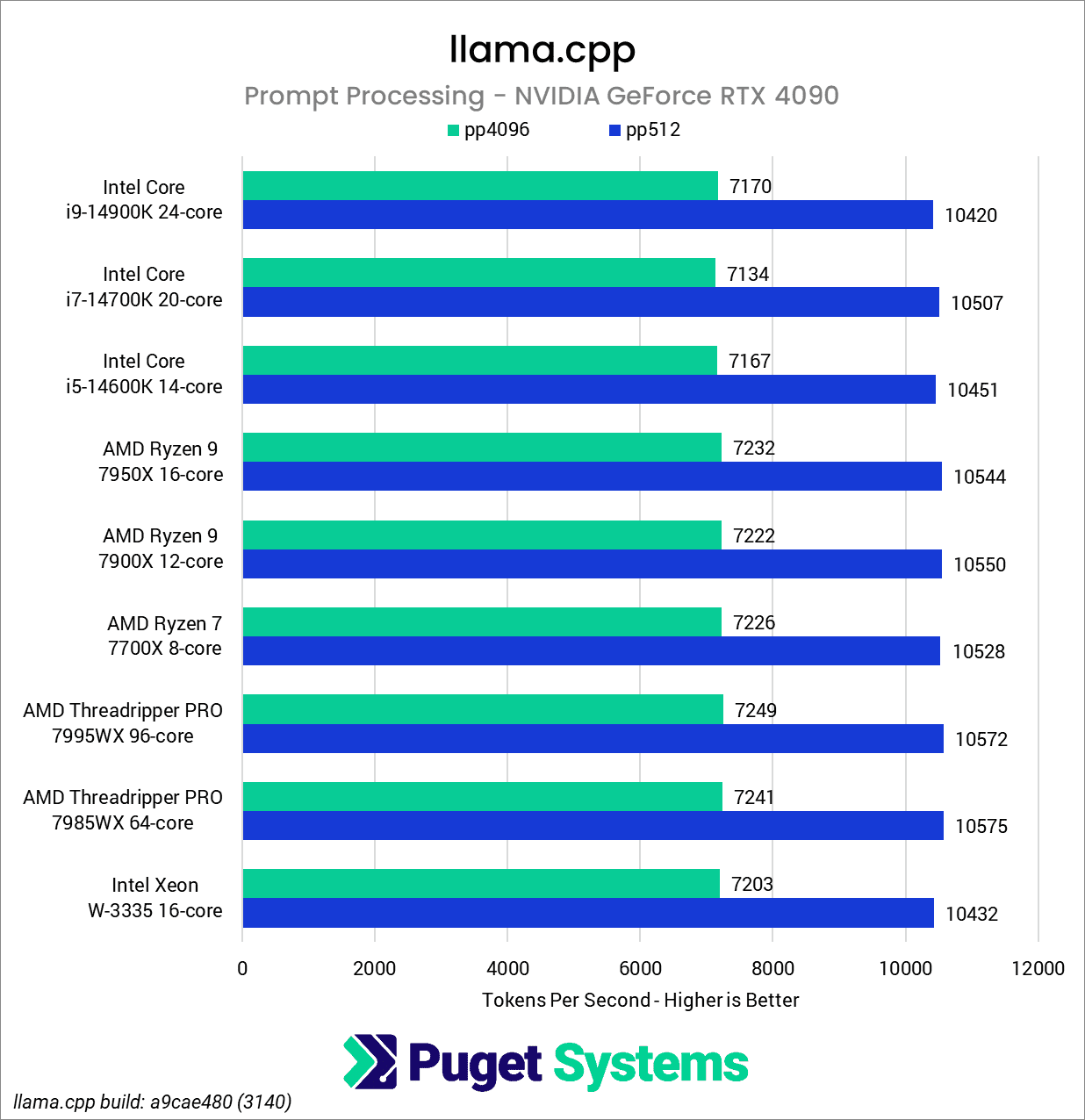
Starting with prompt processing, with either the NVIDIA RTX GeForce 4080 or 4090, we only found minuscule differences in the results between platforms. Especially considering that we are working with speeds in the several thousand tokens per second, differences of a few hundred tokens per second at most are not only imperceptible, but fall within the margin of error of the tests.
As a side note, these tests are an impressive showcase of the RTX 4090’s performance, with its pp4096 test results achieving 90% of the performance of the RTX 4080’s pp512 test despite an eightfold difference in the size of the context.
System Image
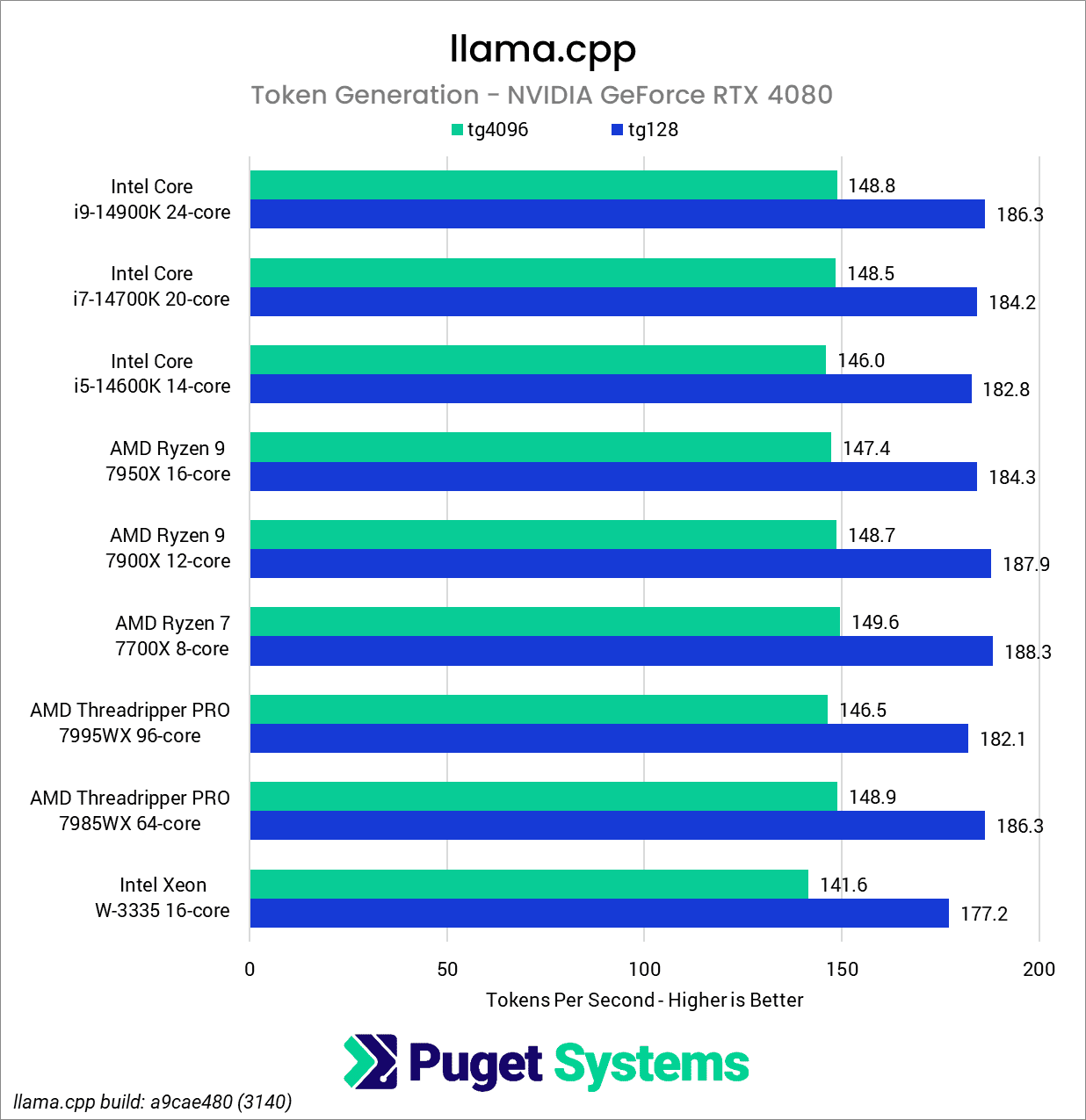
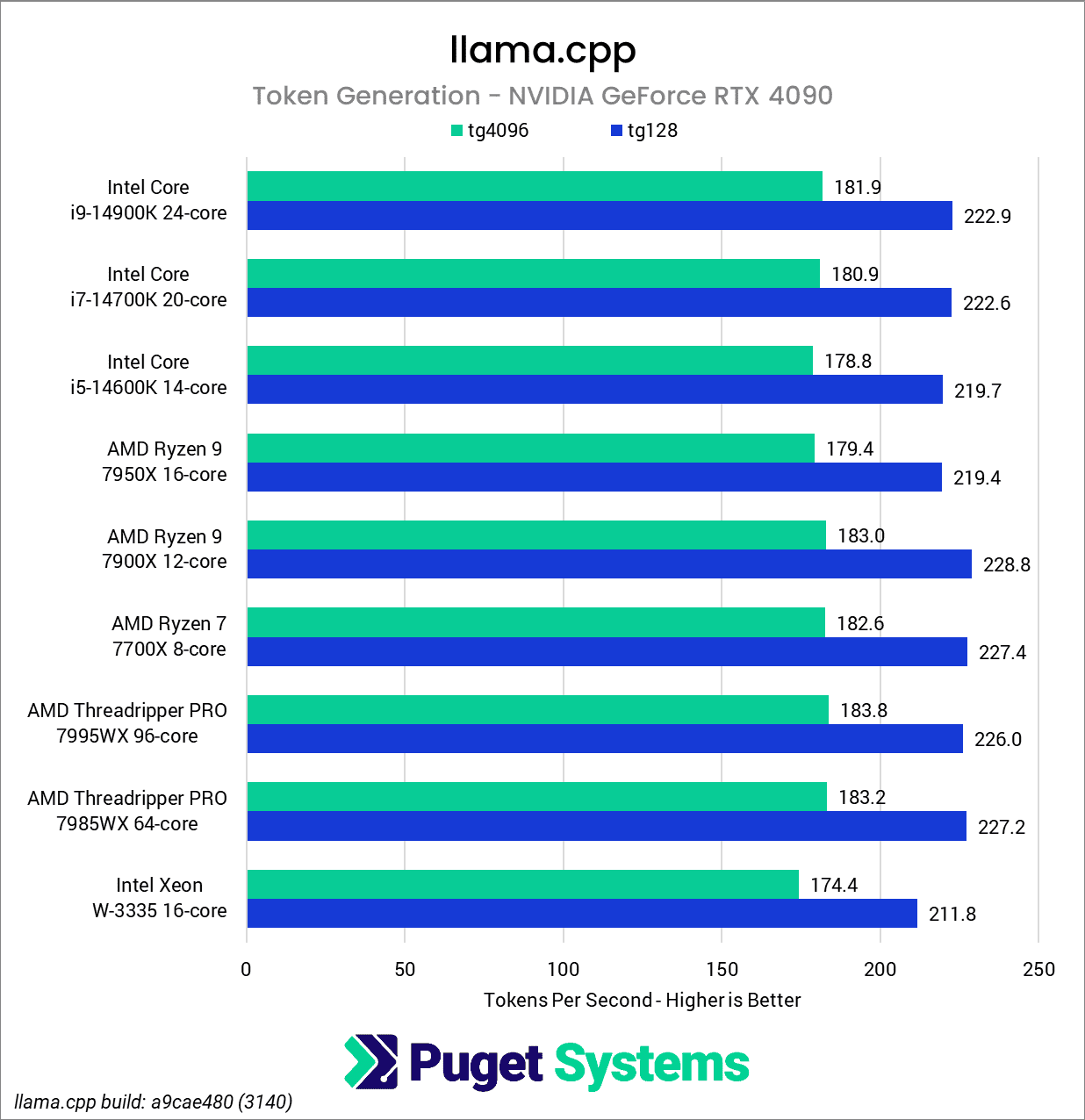
Moving on to token generation, we begin to see more significant differences between the platforms, generally tracking with the processor’s single-core performance. For example, the Xeon W-3335, with its modest Max Turbo speed of 4.0 GHz, consistently obtains the lowest performance of all of the CPUs tested. However, even this only represents about a 5% difference when compared to the other platforms.
Although the i9-14900K has the highest single-core clock speed of the processors we tested, it was surprising that it virtually tied with the Threadripper Pro 7985WX in the RTX 4080-based test and even lagging slightly behind it in the RTX 4090-based test. Another surprise was finding the Ryzen 7 7700X leading ahead of the Ryzen 9 7950X despite having a lower Max Boost. This might have been explained by the fact that the Ryzen 9 7950X uses a dual Core Chiplet Die (CCD) design, which could be introducing some overhead due to inter-chiplet communication; however, the Ryzen 7 7900X is a dual CCD design as well, and it performed similarly to the Ryzen 7 7700X.
To verify this, we did some additional testing, artificially limiting the 7900X to just 2.5GHz and 1.0GHz in two tests with an RTX 4090. When we did so, we received markedly lower results (pp4096 – 167 t/s & 137 t/s, respectively), confirming that CPU performance does indeed affect GPU inference speed. It is simply that most modern CPUs of the latest generation are fast enough that the difference between most of the CPUs we tested is inconsequential. Ultimately, outside of the Xeon W-3335, the results between the processors tested are so close that making meaningful distinctions between them isn’t feasible with this test.


Final Thoughts
Although single-core CPU speed does affect performance when executing GPU inference with llama.cpp, the impact is relatively small. It appears that almost any relatively modern CPU will not restrict performance in any significant way, and the performance of these smaller models is such that the user experience should not be affected. We may explore whether this holds true for other inference libraries, such as exllamav2, in a future article.
In general, this means that if you are using smaller LLM models that fit within a typical consumer-class GPU, you don’t have to worry about what base platform and CPU you are using. Except in a few isolated instances, it should largely be inconsequential and will have a minimal impact on how fast your system is able to run the LLM. However, this test serves as a good reminder that no single component of a system exists in a vacuum and will be affected in some way by the other components in the system as a whole.
Looking for an AI and Scientific Computing workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.